View from the West Coast: Relevance is More Important than Methodological Purity

Bob Slavin published a blog post in which he argues that evaluation research can be damaged by using the cloud-based data routinely collected by today’s education technology (edtech). We see serious flaws with this argument and it is quite clear that he directly opposes the position we have taken in a number of papers and postings, and also discussed as part of the west coast conversations about education research policy. Namely, we’ve argued that using the usage data routinely collected by edtech can greatly improve the relevance and usefulness of evaluations.
Bob’s argument is that if you use data collected during the implementation of the program to identify students and teachers who used the product as intended, you introduce bias. The case he is concerned with is in a matched comparison study (or quasi-experiment) where the researcher has to find the right matching students or classes to the students using the edtech. The key point he makes is:
“students who used the computers [or edtech product being evaluated] were more motivated or skilled than other students in ways the pretests do not detect.”
That is, there is an unmeasured characteristic, let’s call it motivation, that both explains the student’s desire to use the product and explains why they did better on the outcome measure. Since the characteristic is not measured, you don’t know which students in the control classes have this motivation. If you select the matching students only on the basis of their having the same pretest level, demographics, and other measured characteristics but you don’t match on “motivation”, you have biased the result.
The first thing to note about this concern, is that there may not be a factor such motivation that explains both edtech usage and the favorable outcome. It is just that there is a theoretical possibility that such a variable is driving the result. The bias may or may not be there and to reject a method because there is an unverifiable possibility of bias is an extreme move.
Second, it is interesting that he uses an example that seems concrete but is not at all specific to the bias mechanism he’s worried about.
“Sometimes teachers use computer access as a reward for good work, or as an extension activity, in which case the bias is obvious.”
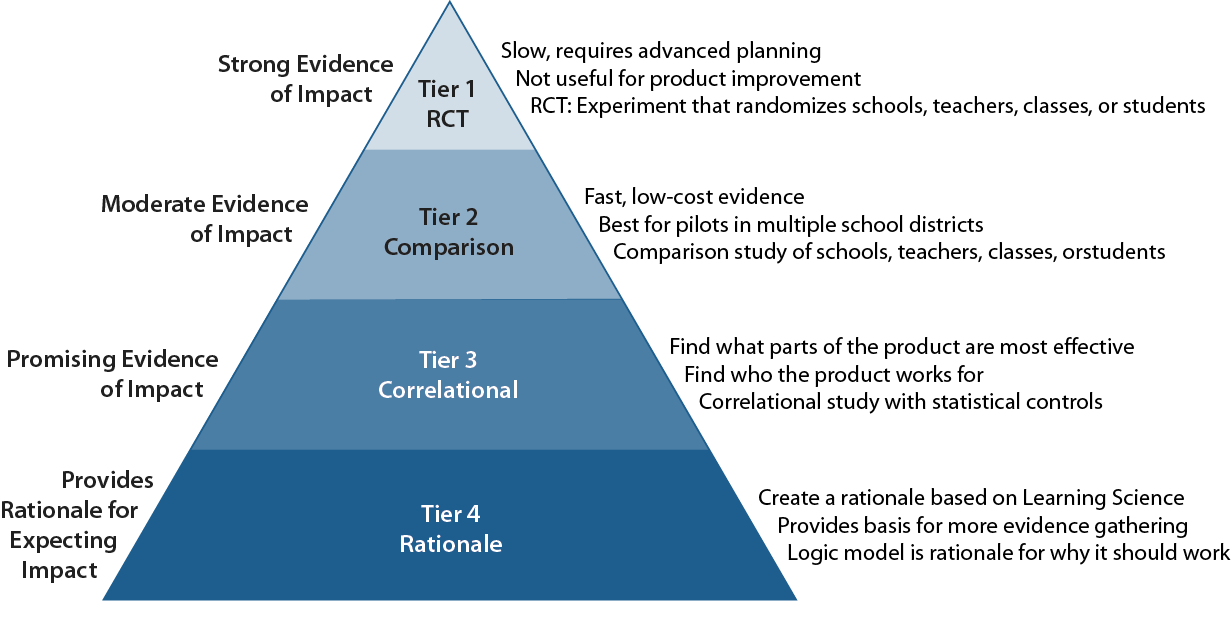
This isn’t a problem of an unmeasured variable at all. The problem is that the usage didn’t cause the improvement—rather, the improvement caused the usage. This would be a problem in a randomized “gold standard” experiment. The example makes it sound like the problem is “obvious” and concrete, when Bob’s concern is purely theoretical. This example is a good argument for having the kind of implementation analyses of the sort that ISTE is doing in their Edtech Advisor and Jefferson Education Exchange has embarked on.
What is most disturbing about Bob’s blog post is that he makes a statement that is not supported by the ESSA definitions or U.S. Department of Education regulations or guidance. He claims that:
“In order to reach the second level (“moderate”) of ESSA or Evidence for ESSA, a matched study must do everything a randomized study does, including emphasizing ITT [Intent To Treat, i.e., using all students in the pre-identified schools or classes where administrators intended to use the product] estimates, with the exception of randomizing at the start.”
It is true that Bob’s own site Evidence for ESSA, will not accept any study that does not follow the ITT protocol but ESSA, itself, does not require that constraint.
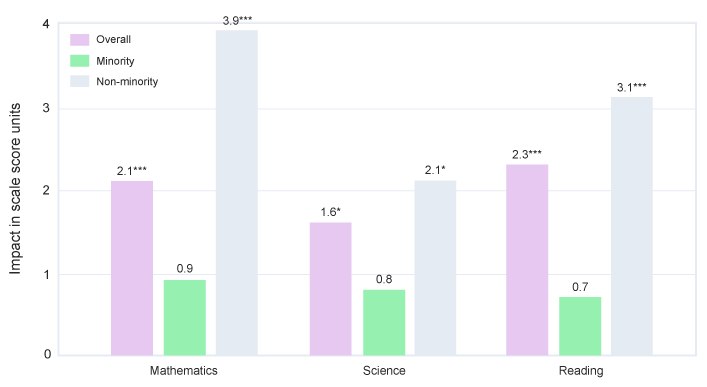
Essentially, Bob is throwing away relevance to school decision-makers in order to maintain an unnecessary purity of research design. School decision-makers care whether the product is likely to work with their school’s population and available resources. Can it solve their problem (e.g., reduce achievement gaps among demographic categories) if they can implement it adequately? Disallowing efficacy studies that consider compliance to a pre-specified level of usage in selecting the “treatment group” is to throw out relevance in favor or methodological purity. Yes, there is a potential for bias, which is why ESSA considers matched-comparison efficacy studies to be “moderate” evidence. But school decisions aren’t made on the basis of which product has the largest average effect when all the non-users are included. A measure of subgroup differences, when the implementation is adequate, provides more useful information.